介绍rocket chip中的inclusive cache。
整体框架
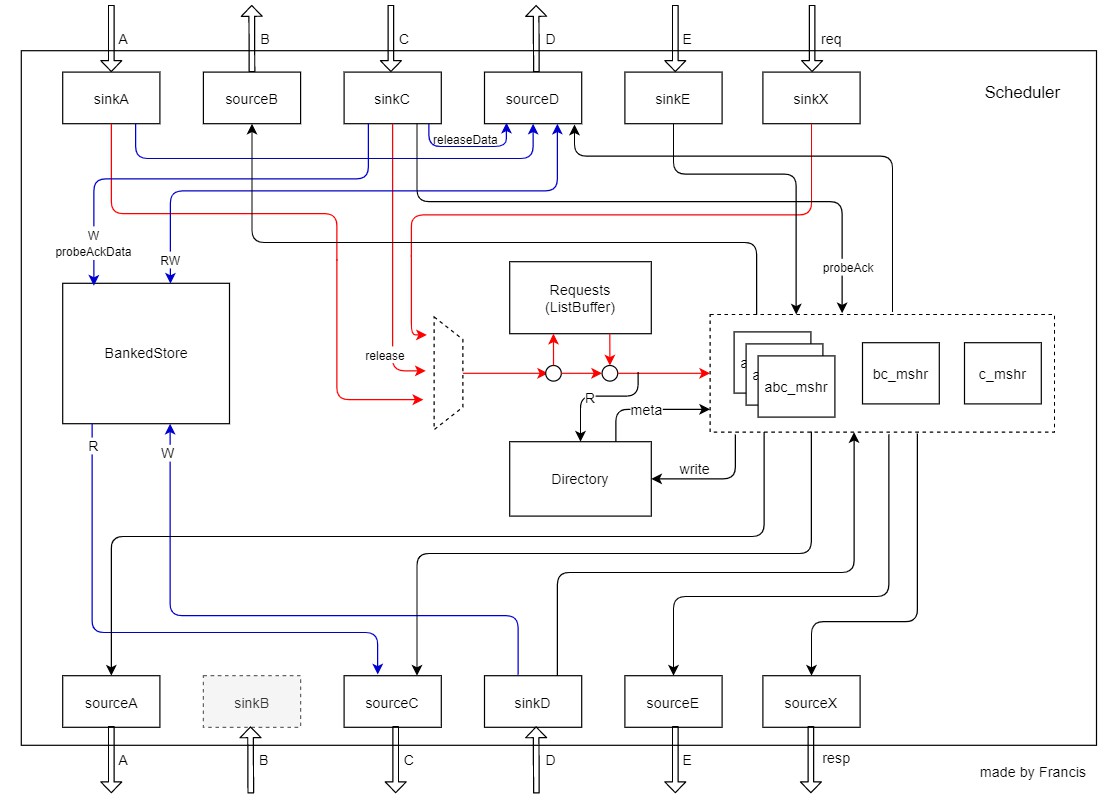
Inclusive Cache中,每个Bank会对应一个scheduler。每个scheduler会有一套独立的处理。
Scheduler的框架如下图所示。包含如下几个部分。其中红线表示内部请求req通道,蓝线表示数据通道。
- sinkA:接收上级A通道的请求,转为req发给MSHR处理
- sourceB:接收MSHR的命令,发送B通道的请求给上级B通道。
- sinkC:接收上级C通道的请求,包括release和probeAck(Data)。如果是release请求就转化为req发给MSHR处理;如果是probeAck(Data)就发送命令给MSHR,数据写入BankedStore。
- sourceD:接收MSHR的命令,读写BankedStore,发送resp给上级D通道。
- sinkE:接收上级E通道的请求,转发给MSHR
- sinkX:接收上级CMO的请求,转为req发给MSHR
- sourceA:接收MSHR的命令,发送请求给下级通道
- sinkB:因为inclusive cache不支持作为中间级cache,所以没有sinkB
- sourceC:接收MSHR的命令,从BankedStore读取数据,发送请求给下级C通道
- sinkD:接收下级D通道来的命令和数据,一方面把数据写入BankedStore,另一方面发送命令给MSHR
- sourceE:接收MSHR的命令,转发到下级E通道
- sourceX:接收MSHR的resp,转发
- BankedStore:cache的data部分
- Directory:保存directory的结构
- Requests:保存请求,里面是个listBuffer,有3MSHR个数的队列,每个队列对应MSHR abc。
- MSHR:每个req的处理,里面是个大状态机。
- scheduler:内部有不少逻辑,用来处理req的调度
ListBuffer
先来看一下inclusive cache里用到的一个特殊的数据结构,叫ListBuffer,简而言之,它就是个buffer,用来保存数据的,那为什么叫listBuffer呢,来看下下面这张图。
这个ListBuffer里共有8个entry,可以被用来保存数据。而且共有2个queue,每个queue是一个单独的链表。在初始状态,所有的entry都是unused,没被使用,是空的。外面可以申请一个entry,将其挂入queue0中。假设外面对queue0申请了3个entry,对queue1申请了2个entry,就变成了如下图的数据结构。
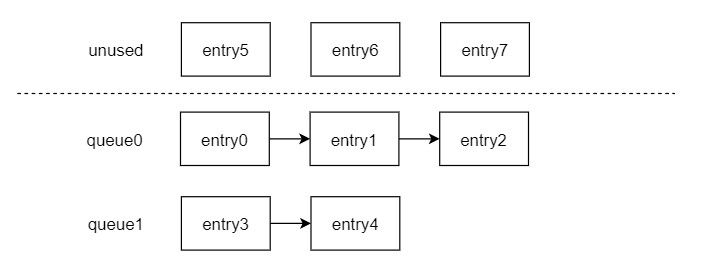
也就是说,ListBuffer可以有entries个空间用来保存数据,有queues个队列用来排队,所有的queue共用entries个的存储空间,而每个queue又是独立排队的。
1 | case class ListBufferParameters[T <: Data](gen: T, queues: Int, entries: Int, bypass: Boolean) |
这样就能理解以上代码中:
- T :表示一个数据结构,也就是要保存的数据结构,作为参数传递进来
- queues:表示里面有多少个队列,需要独立排队的
- entries:表示里面有多少个entries,用来保存数据的。
- index:表示要push到那个queue里面去排队
1 | class ListBuffer[T <: Data](params: ListBufferParameters[T]) extends Module |
1 | val valid = RegInit(UInt(0, width=params.queues)) |
上面代码构建了ListBuffer的主要数据结构,分别是:
- valid:各个队列是否有数据
- head:各个队列的头指针,里面保存的是该队列第一个数据的序号
- tail:各个队列的尾指针,里面保存的是该队列最后一个数据的序号
- used:所有entry是否被使用的标识。
- data:所有entry保存的数据内容。
- next:最难理解的是这个结构,它是所有entry指向下一个指针的链表。
以上面的图作为例子,假设有2个队列,8个entry,展示下各数据结构的内容。
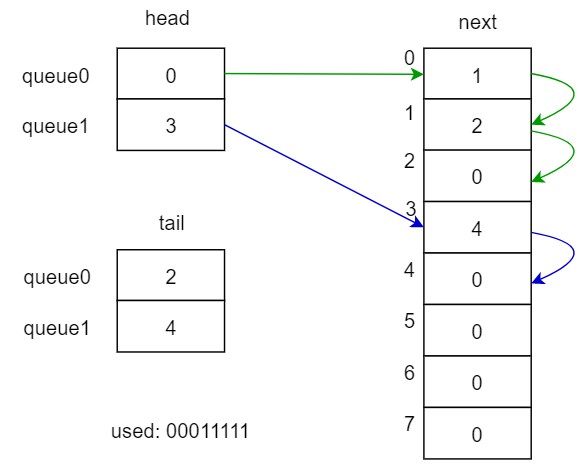
从上图可以看出,由head就能拿到queue0的第一个数据的index,再用这个index查找next,得到1,也就是0的下一个entry是1,再去next查1的下一个,得到2,然后发现2已经和tail里的值相等了,说明已经是尾巴了,从而完成链表的索引,得到了上面图的链表结构。
1 | val freeOH = ~(leftOR(~used) << 1) & ~used |
leftOR: 从低往高找,遇到1就停,把剩下的高位全置一。比如:
b0101 -> b1111
b1010 -> b1110
b1000 -> b1000
OHToUINT: return the bit position of the sole high bit of the input bitvector。assume exactly one high bit. results undefined otherwise.
- b0100 -> 2.U
上面这两句举例来说明。
| used | ~used | leftOR(~used) | leftOR(~used)<<1 | ~(leftOR(~used)<<1) | ~(leftOR(~used)<<1) & ~used | OHToUInt(freeOH) |
|---|---|---|---|---|---|---|
| 0101 | 1010 | 1110 | 1100 | 0011 | 0010 | 1 |
| 1010 | 0101 | 1111 | 1110 | 0001 | 0001 | 0 |
可以看出,freeIdx就是拿到used中最低位为0的位索引,也就是拿到一个可用的位置。
1 | val valid_set = Wire(init = UInt(0, width=params.queues)) |
最后再来看看里面的数据结构,head、tail、next是怎么组织起来的。举例说明。
- 初始used为0,那最低可用的就是freeIdx为0,valid也为全0
- 收到一个push请求,index是1,source是40
- 下一拍。70行data[0]的值被写为40。因为valid[1]为0,所以push_valid为0,走74行分支,head[1]的值被写为0。76行tail[1]的值为写为0。valid[1]的值被写为1,表示index为1已有一个请求了。
- 又收到一个push请求,index还是1,source是80
- 下一拍。70行data[0]的值被写为40。因为valid[1]为1了,所以push_valid为1,走72行分支,next[0]的值为写为1,其中的0是由tail[push_index(1)]读出来的,也就是图中线a;其中的1是当前freeIdx;可以看出next其实是保存了上一个freeIdx到下一个freeIdx的关系。76行tail[1]的值为写为1。
- 又收到一个请求,处理和上面类似。
- 收到一个pop请求,index为1。直接从head[1]里面取到used的index,也就是0,再从used[0]里面拿到40,输出的数据就拿到了。
- 此时还需要更新head的值,根据used的index 0(线b),从next[0]里面拿出下一个used的index(线c),也就是1,再把这个1写入head[pop_index(1)]里面。这样就完成了数据结构处理。
- 当再收到一个pop请求时,同样,从head[1]里面就能取到used[1]的值80了。

总结一下三个数据结构。
head是根据push/pop index来作为地址索引的,head里面的内容是used的地址,根据这个地址作为索引,可以拿到保存的数据。
tail是根据push/pop index来作为地址索引的,tail里面的内容是最后一个used的地址,根据这个可以判断是否该index的请求都处理完了。
next是根据上一个used地址来作为地址索引的,next里面的内容是下一个used的地址,每pop出一个请求,需要将下一个used的地址写入head,以便于下一次pop请求。
也就是说,该模块里面可以根据index来保存一个链表来保存数据。所有的数据共享一个内存data。head、tail、next保存了index到data索引之间的关系。
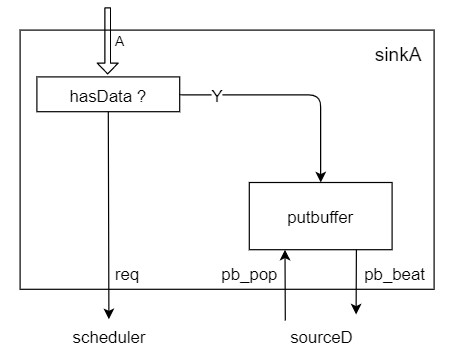
sinkA
sinkA里面就做了下面 几个事情:
- 接收上面A通道来的请求,转化为req发给MSHR
- 如果有数据,就存入putBuffer里
- 接收sourceD来的读数据请求,从putBuffer里把数据给sourceD
1 | // sinkA里putBuffer的entry内容 |
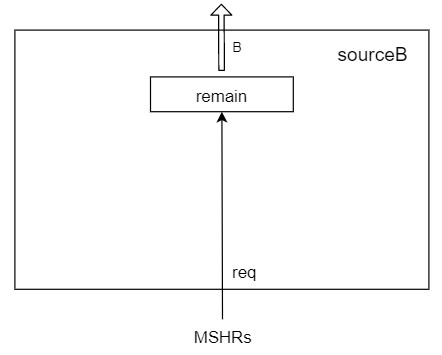
sourceB
sourceB干的事情比较简单,只需要把从MSHR来的请求,转化为向上级B通道的probe就行了。
唯一的数据结构就是remain这个寄存器,用来保存本次probe需要probe哪几个client,在req来的时候置上remain,每发出一个probe就把其中的那bit清零。
1 | class SourceBRequest(params: InclusiveCacheParameters) extends InclusiveCacheBundle(params) |
sinkC
sinkC会根据上面来的C通道请求的类型来走不同分支。如果是probeAck(Data)就走左侧处理流程,如果是release(Data)就走右侧处理流程。
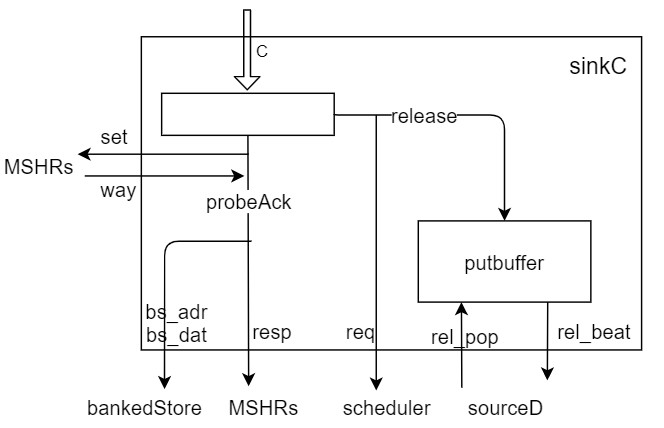
先看左侧probeAck(Data)处理流程。
- 将resp发送给MSHRs
- 去MSHRs通过set查询出要写入的way
- 如果有数据,将数据写入bankedStore。不会进putBuffer了,因为它已经是最老的了,已经分配过MSHR了,不需要排队了。
再看右侧release(Data)处理流程。
- 发送请求给scheduler
- release的数据要进putBuffer,因为它要去排队
- 接收sourceD的读取数据的请求,把数据发送给sourceD,让它写入bankedStore
1 | class SinkC(params: InclusiveCacheParameters) extends Module |
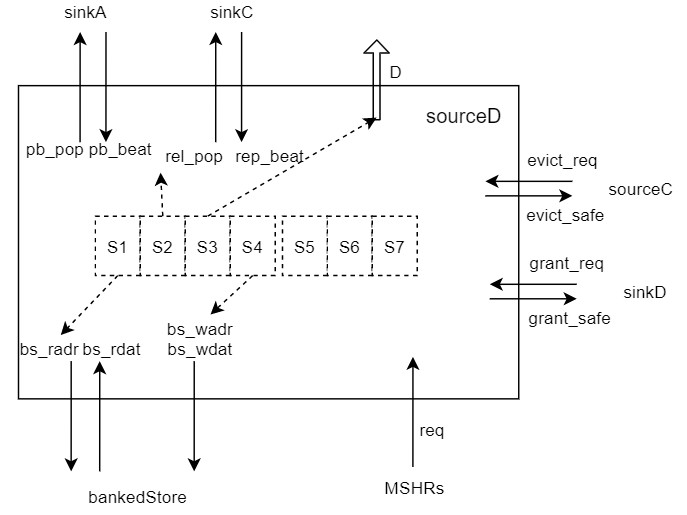
sourceD
sourceD干的事情如下。
- 接收MSHR来的请求。
- 维护一个流水,共7级
- 发读请求给bankedStore
- 发读请求给sinkA/sinkC
- 回应上级D通道
- 发送写请求给bankedStore
- 留三级stage给bypass用
- 响应sourceC / sinkD 过来的查询请求
1 | class SourceD(params: InclusiveCacheParameters) extends Module |
sinkE
就是个消息的转发,什么也没干。
1 | class SinkEResponse(params: InclusiveCacheParameters) extends InclusiveCacheBundle(params) |
sinkX
也是个消息的转发,把接收到的请求,适配到a通道的请求类型上,并把control标记上,表示是从X通道来的请求。
为什么不在前级转?没准很远的地方来的,可以节省线
1 | class SinkXRequest(params: InclusiveCacheParameters) extends InclusiveCacheBundle(params) |
sourceA
也就转下消息类型。
1 | class SourceARequest(params: InclusiveCacheParameters) extends InclusiveCacheBundle(params) |
sourceC
sourceC干的事情如下:
- 接收MSHR过来的请求
- 查询sourceD,是否有hazard的情况,如果有,就等待,如果没有,就可以往下走
- 在s1的时候去bankedStore读取数据
- 在s3的时候把数据拿回来,送到queue里面
- 由queue再发到下级C端口上

1 | class SourceC(params: InclusiveCacheParameters) extends Module |
sinkD
和sinkC的probeAck类似,直接写入bankedStore。
hazard就是如果有相同set/way的在sourceD走流水,就暂缓一下往bankedStore写,因为没有buffer,会挡在口子上。用grant_safe来控制。
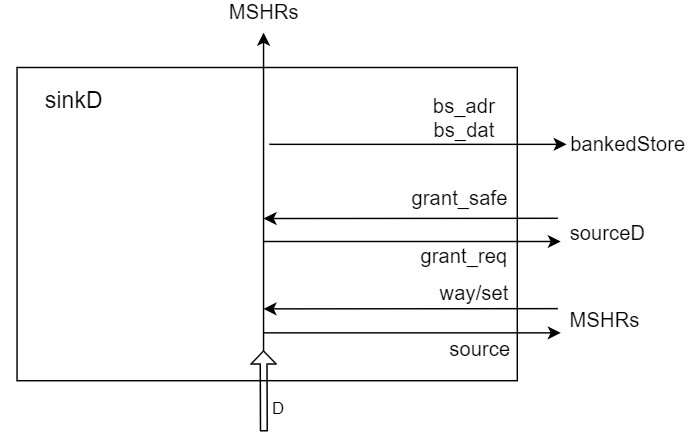
1 | class SinkD(params: InclusiveCacheParameters) extends Module |
sourceE
啥也没有,直接转消息。
1 | class SourceERequest(params: InclusiveCacheParameters) extends InclusiveCacheBundle(params) |
sourceX
啥也没有,直接发response。
1 | // The control port response source |
bankedStore
bankedStore是用来保存数据的,内部又分了多个子bank。它主要处理的事情是:
- 保存cache的数据
- 接收sinkC / sourceD / sourceC / sinkD 来的读写数据请求
- 处理请求的优先级:sinkC > SourceC > sinkD > sourceDw > sourceDr
- 处理数据位宽的转换,内外的数据位宽都可变,bank数根据位宽参数变化
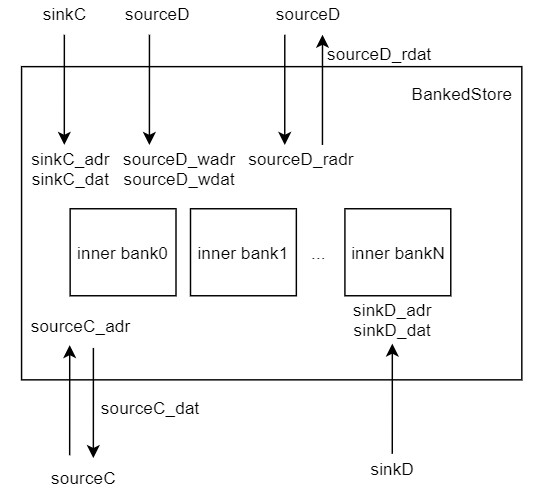
该模块两大比较关键的点。
- 为什么这么设置优先级?遗留问题
- bank的组织方式。一条cacheline是横着放的,会被放在不同bank上,如果burst来的话,就会先访问bank0,再bank1,这样再来一个请求就能流水起来访问了。
1 | abstract class BankedStoreAddress(val inner: Boolean, params: InclusiveCacheParameters) extends InclusiveCacheBundle(params) |
directory
Directory用来保存Cache的Tag。
- 保存Cache的Tag。
- 提供读写端口,供外部读写。
- 在reset之后,初始化SRAM
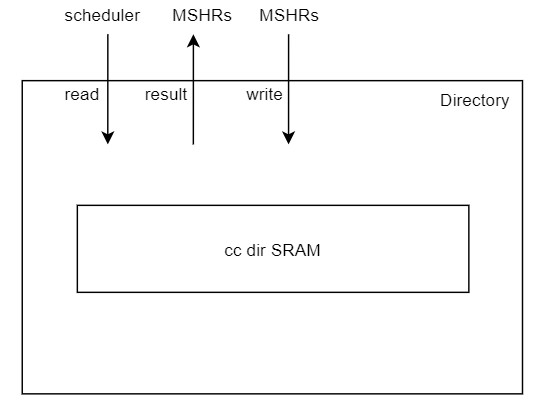
1 | class DirectoryEntry(params: InclusiveCacheParameters) extends InclusiveCacheBundle(params) |
requests
是个listBuffer,共3*MSHR个数的队列。每个MSHR有3个队列,分别对应abc,优先级c > b > a。
Queue里面是没有完整的地址的,只记录了tag,因为MSHR都是同set的在排队的。
如果一个mshr被占住,那其他set的就不会被分配到这个mshr了,只会给它相应队列的请求用。
如果有不同的set的请求,会尝试分配新的mshr,如果没有新的mshr,就会被挡在外面了。
MSHR
MSHR里面主要是一个大的状态机,用来处理一个独立的请求。
在理解MSHR之前,首先要理解几个概念。什么是nestB / blockB / nestC / blockC?
1 | blockB: block住下面来的同set的B请求。 |
1 | class QueuedRequest(params: InclusiveCacheParameters) extends InclusiveCacheBundle(params) |
scheduler
scheduler主要负责调度请求。
1 | class Scheduler(params: InclusiveCacheParameters) extends Module |
configs
memCycles: Int // 是从L2到memory的latency是多少,在parameter.scala里面计算的。是假定在这么多cycle内DDR能回我多少个transaction,从而我就需要多少个MSHR来接收,也就是MSHR至少需要多少个才能满足DDR的需求,超过这个值才能让MSHR不变成瓶颈。
parameter里117行。50ns是外面DDR的延时,800MHz是L2C的频率。所以是40个cycle的latency。(如果L2C是1.8G,那大概90个cycle)
scenario
scenario 1
MSHR中如果w_grantfirst就不能nestedB。
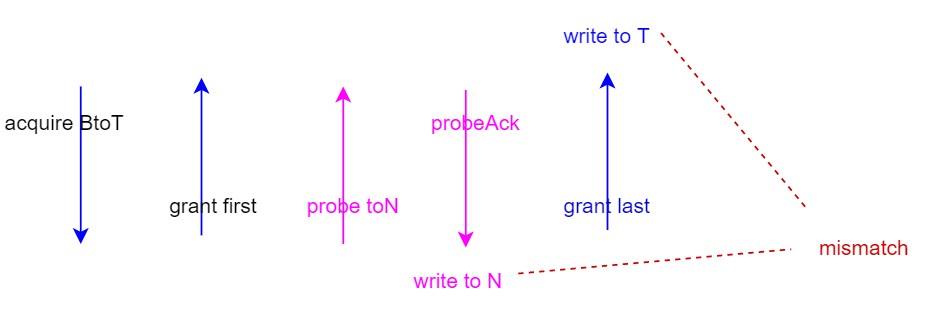
scenario 2
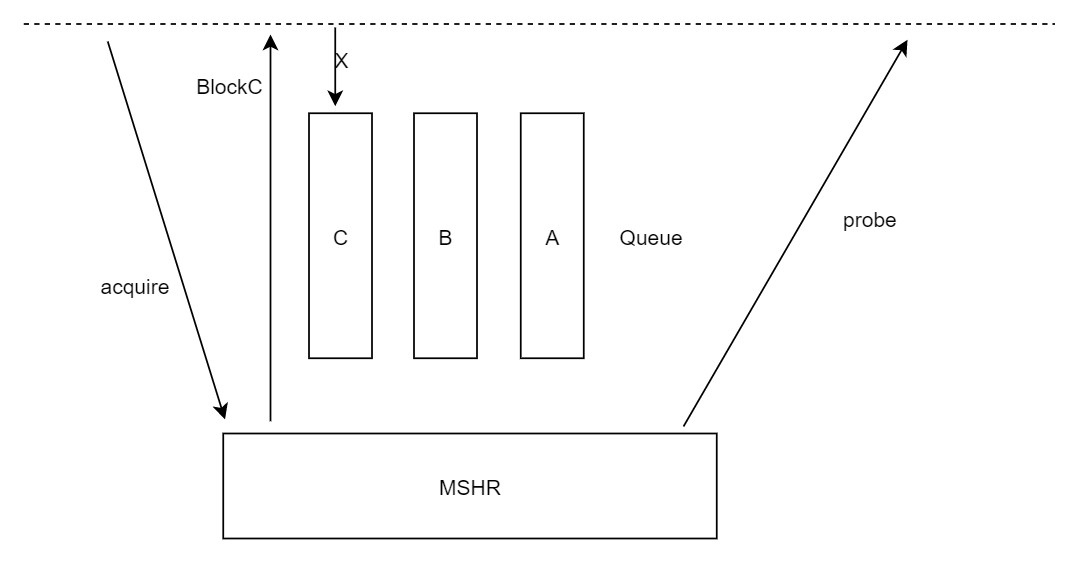
假设有一个acquire进到MSHR里面,在meta_data还没读出来的时候(也就是不知道directory状态的时候),会把blockC拉高,这样在scheduler里面会把C通道的请求都挡在接口上,等到blockC拉低,再来判断C通道的请求是不是可以nestC,如果可以就nest,如果不行就进queue。
如果没有这个blockC,而是让C通道的请求直接进queue的话,那有可能出现问题。比如在meta_data没准备好的时候来了个releaseData,发现不能nest,就进queue,等MSHR查出directory之后,releaseData已经进到queue里排队了,不会再来nest了,MSHR就处理acquire,发probe上去,上面回NtoN,从而忽略了releaseData,最新的data就留在了queue里,没拿到,导致问题。
也就是说一个请求的过程中,会出现三种情况:
- block:把外面的请求挡在接口上,不能进queue,也不能进MSHR,这种最为严格,因为此时状态还不确定,没法做判断,挡住最保险
- nest:可以被插队,当前状态已经比较明确了,并且可以被别人插队
- 非block非nest:不能被插队,当前状态也比较明确了,但是当前请求比外面的请求优先级高,就先做当前请求,让外面的请求进queue排队处理。